Audio¶
Audio is the most important part of video. It is also the most neglected part in most amateur productions; it is easy to care about full-HD productions but never remember to give the speaker a microphone. Your stream can live with blurry or murky pictures, but it cannot live with people not hearing what’s being said.
Nageru aims to give the operator meaningful, useful controls for processing and mixing audio, with a focus on voice. There are two modes for audio processing, namely simple and multichannel; they are selectable from the audio menu.
Be aware that a mix that sounds good on a PA system will not necessarily sound good on a stream; PA systems often have rather different audio characteristics than a set of home speakers or headphones, and there will also frequently be other sounds in the room that remove some of the typical “dryness”. However, for simple use, reusing such a mix isn’t the worst choice you can make.
Simple mode¶
Simple audio mode is the default. Despite its name, it contains a powerful audio processing chain; however, in many cases, you won’t need to understand or twiddle any of the knobs available.
Simple mode allows input from only a single source, and that source has to be one of the capture cards. (You choose which one by right-clicking on its channel and selecting it as audio source.) The two typical cases where this is useful are:
When you simply take in audio from one of the cameras, possibly by way of external microphone, or
When you have an external mixer and can embed its output in one of the video inputs.
If you want more than one audio source at a time, or if you want to use ALSA inputs, you will need to use multichannel mode; it is more complicated, but it is a strict superset of what the simple mode can do. (In fact, simple mode constructs a multichannel setup behind-the-scenes and then runs the multichannel audio code.)
Audio meters¶

When setting overall audio levels, there are two important goals: To keep a reasonable perceived loudness, and to avoid clipping. Both are more subtle to measure than one would initially assume, and there are many ways to misstep. In particular, pretty much any naïve way of measuring loudness will fail; human hearing is, for instance, much more sensitive in some frequencies than others.
EBU R128 provides solid solutions to both problems. It specifies a precise algorithm to calculate a both momentary loudness (over short and medium time intervals; Nageru uses the short measurement), and a loudness range over an arbitrary amount of time. The loudness is measured in LU (loudness units), which is a relative unit very much like decibels; there’s also LUFS (loudness unit relative to full scale), which is number of LU compared to a given reference.
EBU R128 specifies a target loudness (0 LU) of -23 LUFS +/- 1 LU; if you keep your stream within this and don’t have a huge range in general, it will have a reasonable loudness on most viewers’ setups. The left meter shows the momentary loudness (over the short 400 ms intervals), and the right meter shows the loudness range, with the target shown as a box. If you are within the target, the box turns green; otherwise, it is red. Both meters show 1 LU as one segment, with the highest value being +9 LU (compared to the reference level) and the lowest being -18 LU.
Even if the overall loudness is correct, one needs to avoid clipping; if samples go outside the allowed range, it will sound as clicking or popping (or if many do, as extreme distortion). However, just measuring the value of every single sample is not good enough; since the client might do its own resampling and processing, we also need to account for inter-sample peaks. Nageru, in line with R128 recommendations, oversamples the audio by 4x and writes the highest peak (in dBFS) below the left meter. Anything above the R128 limit of -0.1 dBFS will make the meter turn red to alert the operator that clipping has occurred. (In practice, this should rarely happen due to the limiter; see the next section.)
You can click the reset (RST) button to reset all the meters, including the peak measurement.
Finally, the very top contains a correlation meter measuring the correlation between the left and right channel, which is useful for checking the stereo image. It goes from -1 at the very left (the channels are exact opposites of each other), via 0 in the middle (the channels are totally uncorrelated), to +1 at the very right (the channels are exactly the same). All of these are indications of common issues:
A correlation meter that sits at exactly zero typically means either the left or the both channel (or both) is silent.
A correlation meter that sits at exactly +1 typically means you are sending a mono stream. This could be intentional (if you e.g. have only a single microphone), but if not, it could indicate either a loose connector or stereo channels panned wrong.
Finally, a correlation meter that sits at negative values for longer periods of time indicate that one of the channels is inverted (the phase is wrong), and could sound odd on speaker setups. However, certain kinds of reverb or other effects could also cause this, so it could be benign.
A healthy stereo stream will usually have a correlation somewhere around 0.7–0.8, and this section is marked in green.
The audio strip¶
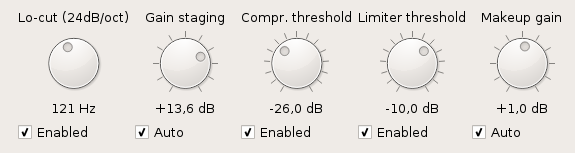
The audio strip contains controls for the processing chain for the audio from start to end, left to right. Note that by default, everything is enabled; if you have a pre-made audio mix that you are confident that you want 1:1 into the stream, you can start Nageru with the “–flat-audio” flag, that instead starts with everything disabled.
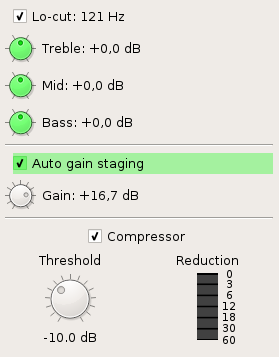
The first step in the pipeline is a lo-cut (or equivalently, highpass) filter. The exact cutoff frequency is a bit a matter of taste (and also depends on the speaker), but the main point is that it gets rid of low-frequency hum and a lot of the background noise that is not related to the speaker’s voice. (If you were producing music, you’d probably want it there to make room for music under it, but then you’d want it higher than the default 120 Hz.)
Next comes a chain of no less than four compressors. They are based on the same basic structure, but have very different settings, and fill very different roles.
The first compressor is the gain staging, or auto-leveler; it is very slow, with 500 ms attack time and 20 second release time. Its purpose is to set the overall level for the next compressor in the chain (so that it is slightly over its threshold); if you have a pretty consistent input signal, you can uncheck the “Auto” box and just set a static value manually.
The second compressor is the actual compressor. It is much faster, with typical voice settings (5 ms attack, 40 ms release). It has the effect of making the voice sound a bit tighter, more level and overall better; if you have multiple things in the mix, it will also bring them somewhat closer together. (In general, a compressor gives the signal less dynamic range by making it quieter, which allows you to gain it more up in a later stage, so that it can get louder overall. It’s a bit paradoxical if you’re not used to it.)
You can adjust the threshold if you wish, or disable the compressor altogether if your signal is already mastered. Note that if the gain staging is not set so that this compressor gets an input signal that’s loud enough, it won’t do anything to it.
At this point, the mastering section begins; for simple audio, the distinction won’t matter, but for multichannel, the previous effects are separate per-bus and the remaining are applied after the mix. (More on this below.) The mastering section begins with a limiter, basically a compressor with very high ratio. It’s there as an emergency brake for really loud sounds that got through the other compressors—a classic example is a speaker suddenly coughing, or a very loud bass drum. This prevents both clipping and blowing out the speakers’ ears.
At this point, the audio signal is almost where we’d like it to be, but the overall sound level might not be quite right. All the previous compressors have been working in the objective domain, but as explained in the previous section, this does not necessarily correspond to the desired overall audio loudness. (Their default levels have been calibrated so that they end up around 0 LU for typical speech content, but they could easily miss by a few LU in many cases.)
Thus, there’s a final makeup gain at the end to compensate for these issues. When the “Auto” checkbox is ticked, which is by default, it will very slowly (filter constant of 30 seconds) adjust itself so that the overall level goes toward 0 LU, ie., the reference level. It is so slow because the R128 calculations inherently must go over a certain amount of time (what we want to change with this gain is the overall sound level, not the immediate one). In periods where the makeup gain is far off, such as when the stream is all silent, it doesn’t update at all. As with the other knobs, you can uncheck the “Auto” checkbox and tune this yourself if you want to.
Multichannel mode¶
Multichannel mode expands on simple audio mode by allowing you to have multiple buses of audio. (In a sense, it could more accurately be called “multibus mode” instead, but the name would be too confusing.) A bus in Nageru is a pair of channels (left/right), sourced from a video capture or ALSA card. The channel mapping is flexible; my USB sound card has 18 channels, for instance, and you can use that to make several buses. Each bus has a name (for instance, something like “Blue microphone” or “Speaker PC”), which is just for convenience; Nageru doesn’t care what you write here, but the labels are useful for the operator.
Input mappings¶
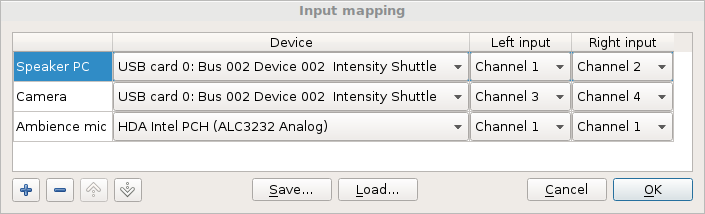
The input mapping dialog should be pretty much self-explanatory; you can use the + button to add a new bus, and the - button to remove the currently selected one (you select by clicking on it). The up and down buttons rearrange the order by moving the currently selected bus up or down, if possible. Note that you can create a mono bus by assigning the same input channel to the left and right inputs.
Because mappings can be tedious to setup, you wouldn’t want to set up a complicated one every time you started Nageru. Therefore, mappings can be saved and loaded from disk; the stored file is a protocol buffer in textual format. You can also load one at start with the “–input-mapping” parameter, which also implies multichannel mode (–multichannel).
Nageru strives to keep the mapping consistent even in the face of a changed environment—for instance, if you unplug and replug a USB sound card, Nageru will attempt to keep your buses mapped to that card still mapped. (While the card unplugged, the main display will show the relevant buses as “(disconnected)”.) Similarly, if an ALSA device is taken by another program on startup and cannot be accessed by Nageru, it will mark it as “(busy)” and try again in the background. However, there are edge cases where Nageru simply cannot do the right thing, for instance if you unplug two identical cards and plug them back in the reverse order; USB cards don’t carry any kind of serial number or other forms of unique identification.
The audio views¶

Once multichannel mode is active, the audio view selector (up to the right, just below the level meters) gains a third option. The arrows (or equivalently, the PgUp/PgDown keys on the keyboard) allow you to select between those three views:
In the compact audio view (which is the default), each bus is represented only by its label, its peak meter (see below) and its fader. This takes up little screen estate, and allows the video channels to be visible. This is the typical view you’d use once you’ve set up everything and are actually doing live video editing; the controls from the full audio view are still in effect, but you cannot see or interact with them.
The video grid display does not have any audio controls, but tries to use as much screen estate as possible on the video channels only. In particular, it can put the channels in multiple rows if that facilitates larger previews, which can be useful if you have many channels.
The full audio view (only available in multichannel mode) contains a lot more controls, but leaves no room for the video channels. These are useful when you are doing initial setup of your mix, or if you want to go back and tune something. The full audio view will be described in detail in the following section; the interpretation of the corresponding controls in the compact audio view is the same.
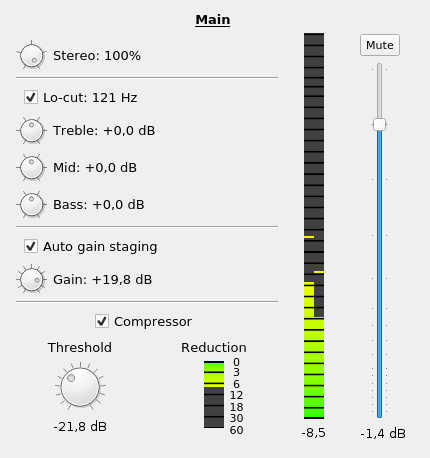
There’s one set each of these controls for every bus. The most important parts of the mix are given the most screen estate, so even though the way through the signal chain is left-to-right top-to-bottom, we’ll go over it in the opposite direction.
By far the most important part is the audio level, so the fader naturally is very prominent. (Note that the scale is nonlinear; you want more resolution in the most important area.) Changing a fader with the mouse or keyboard is possible, and probably most people will be doing that, but Nageru also supports USB faders (see MIDI controllers). There’s a mute button if you just want to silence a bus temporarily; it has exactly the same effect as pulling the fader all the way down, ie., it will make the bus go all silent.
Then there’s the peak meter to the left of that. For each bus, unlike for the meters used for mastering (see Audio meters), you don’t want to know loudness; you want to know recording levels, so this is a peak meter, not a loudness meter. (There’s some holdoff so you can see the actual peaks over a short period.) In particular, you don’t want the bus to send clipped data to the master (which would happen if you set it too high); Nageru can handle this situation pretty well (unlike most digital mixers, it mixes in full 32-bit floating-point so there’s no internal clipping, and the limiter described in The audio strip will usually save you) but it’s still not a good place to be in, so if you peak, the historical peak label under the meter will go red if it happens. If you want to reset it, click on it using the mouse.
The peak meter doubles as an input peak check during setup; if you turn off all the effects and set the fader to neutral, you can see if the input hits peak or not, and then adjust it down. Left and right channel are shown separately, so you can see if they are approximately the same level or even completely mono.
The compressor is well-known from the simple audio mode, but in this view, it also has a reduction meter, so that you can see whether it kicks in or not. (This is also nonlinear, and each step is marked with number of decibels the compressor had to reduce the signal.) Most casual users would want to just leave the gain staging and compressor settings alone, but a skilled audio engineer will know how to adjust these to each speaker’s antics—some speak at a pretty even volume and thus can get a bit of headroom, while some are much more variable and need tighter settings.
Nearly at the top (and nearly first in the chain), there’s the EQ section. The lo-cut is again well-known from the simple audio mode (the filter is separate for each bus, the cutoff frequency is the same across all buses), but there’s now also a simple three-band EQ per bus. Ask the speaker to talk normally for a bit, and tweak the controls until it sounds good. People have different voices and different ways of holding the microphone, and if you have a reasonable ear, you can use the EQ to your advantage to make them sound a little more even on the stream. Either that, or just put it in neutral, and the entire EQ code will be bypassed.
Finally (or, well, first), there’s the stereo width knob. At the default, 100%, it makes no change to the signal, but if you turn it to 0% (at the middle), the signal becomes perfect mono. Between these two, there’s a range where the channels leak partially over into each other. This can be useful if you have a very hard-panned signal (say, two microphones that point in diametrically opposite directions), which can sound odd when the listener is using headphones. Going further to the left, at -100%, the left and right channels are exactly swapped and between -100% and 0% is again a reversion with partial leaking. The range between -100% and 0% is for convenience only, as you could achieve the same effect by swapping the two channels in the input mapping. Note that the entire control is grayed out if the signal is provably mono (ie., the same input channel is mapped to both left and right).
MIDI controllers¶
If you are doing audio work beyond just setting up a mix and letting it stay there, dragging controls with the mouse can feel limiting. There’s a wide range of controllers out there that have physical faders and knobs you can twiddle for a much more tactical feel; all the way up from about $50 to more than $5000. (For reference, Nageru has been tested with the Akai MIDImix and the Korg nanoKONTROL2, and both work fine, although the nanoKONTROL2 needs some one-time Korg-specific SysEx commands before the lights and buttons will work with Nageru.) Nageru supports these in multichannel mode only.
For historical reasons, these speak the MIDI protocol as if they were instruments, and thus, Nageru refers to them as MIDI controllers. However, you won’t really notice; they come with USB plugs to transport the MIDI data, so you just plug them in and have Nageru automatically talk to them. (For simplicity, Nageru will assume any MIDI device connected to your machine is such a controller.)
Since different controllers have different numbers of faders, knobs, buttons and lights, you will need to make a mapping. However, just like with the audio input mapping, this can be done once and then saved to disk for later loading. (You can load a given mapping on startup using the “–midi-mapping” flag.) The dialog, loaded with the included preset for the Akai MIDImix, looks like this:
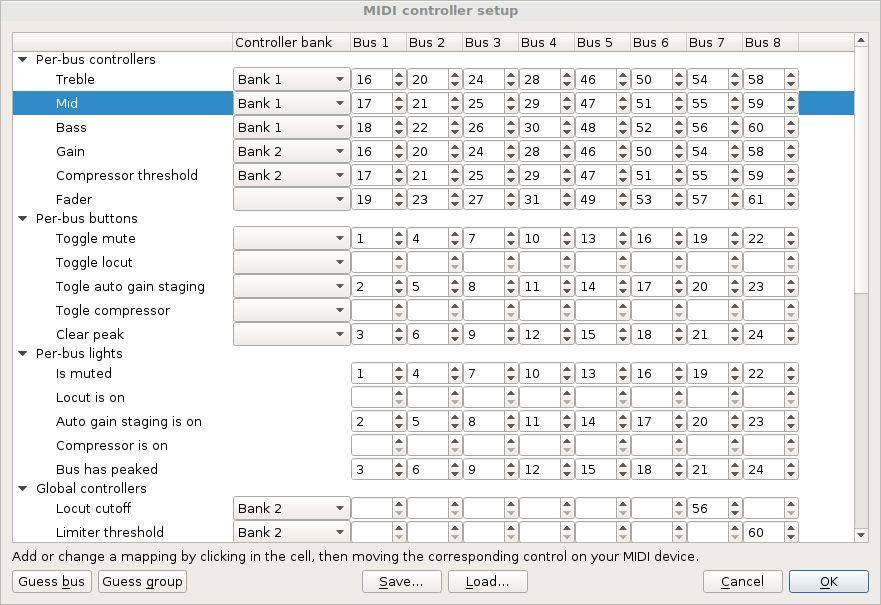
There are three types of controls, which correspond to different types of MIDI events:
Controllers map directly to MIDI controllers (the value in the dialog is the controller number), which are continuous values that can take on values from 0 to 127. (Unfortunately, MIDI was made in the 80s, where 7-bit precision was seen as enough.) They are typically used for faders and knobs.
Buttons are one-shot events that map to MIDI note-on events, and the value in the dialog is the MIDI note number (also from 0 to 127). They are similar to mouse buttons in that they don’t have an on or off state (the MIDI note-off events are ignored). A typical example would be a mute button that can be pressed to either mute or unmute a channel.
Lights are output events where Nageru can send feedback to the controller (and by extension, the user), represented by MIDI note-on and note-off events (to turn the light on or off). A typical example would be a mute light, that is on when a channel is muted.
In addition, each event can be per-bus or global. It can be a bit confusing that even the global events can be set once per-bus, but this is merely a convenience, allowing you to bind multiple physical controls to the same global controller; for global controllers, the bus number(s) you use for your mapping do not matter.
The combination of controller type and per-bus/global constitutes a mapping group, clearly marked and collapsible in the UI.
Creating and updating mappings¶
Unless you have a reference sheet for your MIDI controller, specifying which controller and number numbers the different physical knobs and faders emit, inputting these numbers by hand can be a frustrating procedure. (Actually, even with a reference sheet, it probably is.) Thus, the preferred way is by autosensing; select the given mapping with the mouse and use the control you want to bind it to, and Nageru automatically fills it in.
Also, most devices support many channels, with very similar structure in their controller and/or note numbers. Once you’ve filled out one and then started filling out another one, Nageru can guess for you; if it thinks it can make a reasonable guess (ie., find a consistent offset from its left or right neighbor), the “Guess bus” and/or “Guess group” buttons will be clickable. This can save considerable amounts of time, although it is advisable to check Nageru’s guess for at least the first guessed channel. In particular, some controllers do not have a consistent offset between channels on all the controllers (making “Guess bus” give the wrong answer), just on the controller groups, so there, you must limit yourself to guessing only a single controller group (using “Guess group”).
Lights currently cannot be learned, so some trial and error is needed. (However, if there are buttons associated with the light, a good place to start is using the same note number.) However, just like the input controllers, they can be guessed once you have all the mapping you want for a neighboring bus and partial information about the current one.
Controller banks, and UI visibility¶
Many MIDI controllers do not have enough faders and knobs for every Nageru function you might want to control; some even contain only one fader or one knob. Thus, Nageru supports assigning a physical control to multiple functions, through controller banks. If a mapping is assigned to a controller bank, it is only active when that bank is active. The act of switching banks is in itself an action that can be initiated from the MIDI controller; in fact, that is currently the only way to switch them.
A typical example would be having a knob that in bank 1 is assigned to gain, and in bank 2 to cutoff (which happens to be a global control, as described in the previous section). This way, one can switch between the two banks and have both functions accessible from the MIDI controller. Similarly, buttons can be reused by assigning them to multiple banks.
Note that when switching banks, the associated controller(s) is not immediately updated; this happens only when you move the control. Otherwise, a bank switch would cause a host of unwanted changes, as it is unlikely that you would want the control in the exact same position for the two controllers. (There is a similar problem when starting up Nageru for the first time, where the controllers are not necessarily in the place matching Nageru’s startup settings.) Some more expensive controllers support motorized faders, where the host can tell the control to move to the right place and thus solve the problem, but Nageru does not currently support them.
To help you know which bank is active (or even that you have a MIDI controller connected at all), the currently mapped controller have a green activity highlight. When you switch banks, the highlight also updates—a controller is only highlighted if its mapping is active in the currently selected bank. This way, it is easy to see which controllers are currently controllable by MIDI, and which ones that are not.